Deploy Better AI with Intelligent Infrastructure that Continuously Learns and Adapts to Your Workloads

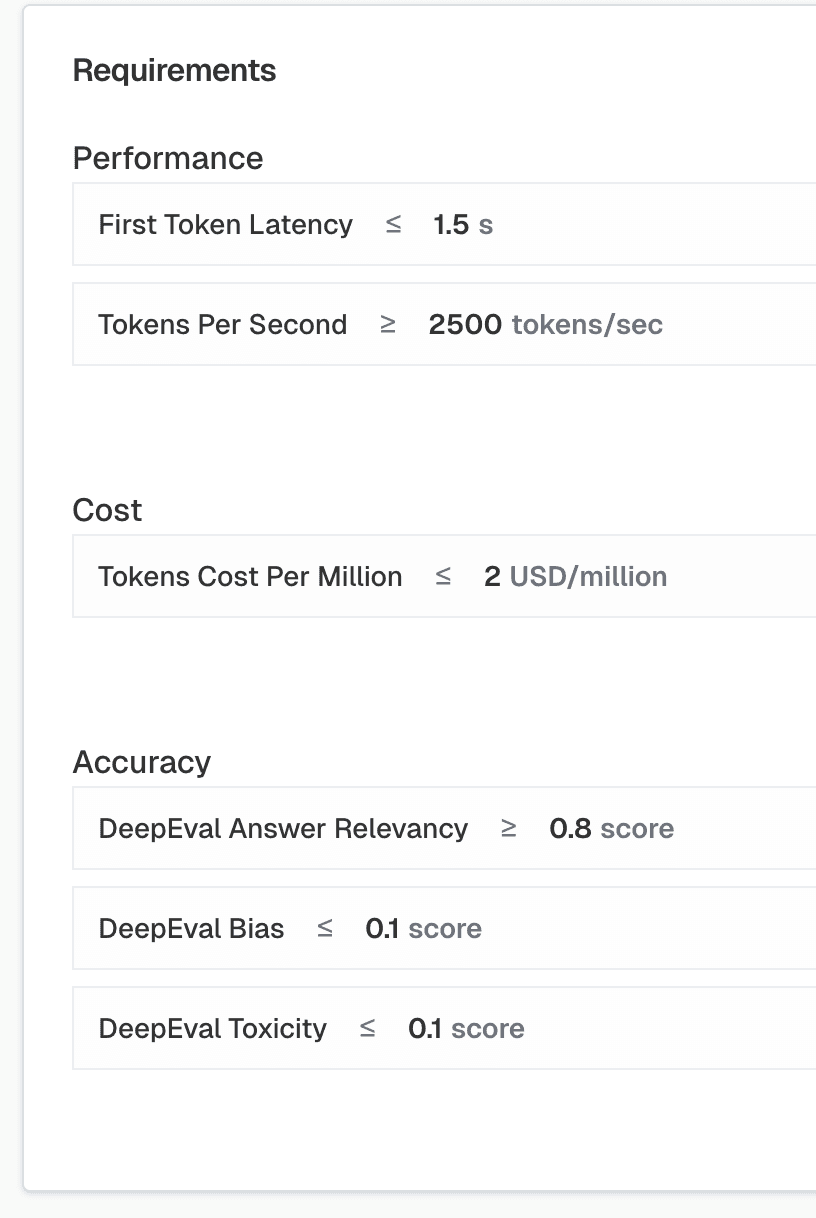


Turn your requirements into production-ready AI in minutes
You define the requirements — we deploy, run, and improve the AI.
Declare your accuracy, latency, throughput, cost, and compliance needs — plus any prompt variations you want to explore.

Influxion assembles and deploys a production AI stack that routes across models, configures prompts, and is designed to meet your requirements. Use it just like a traditional model.
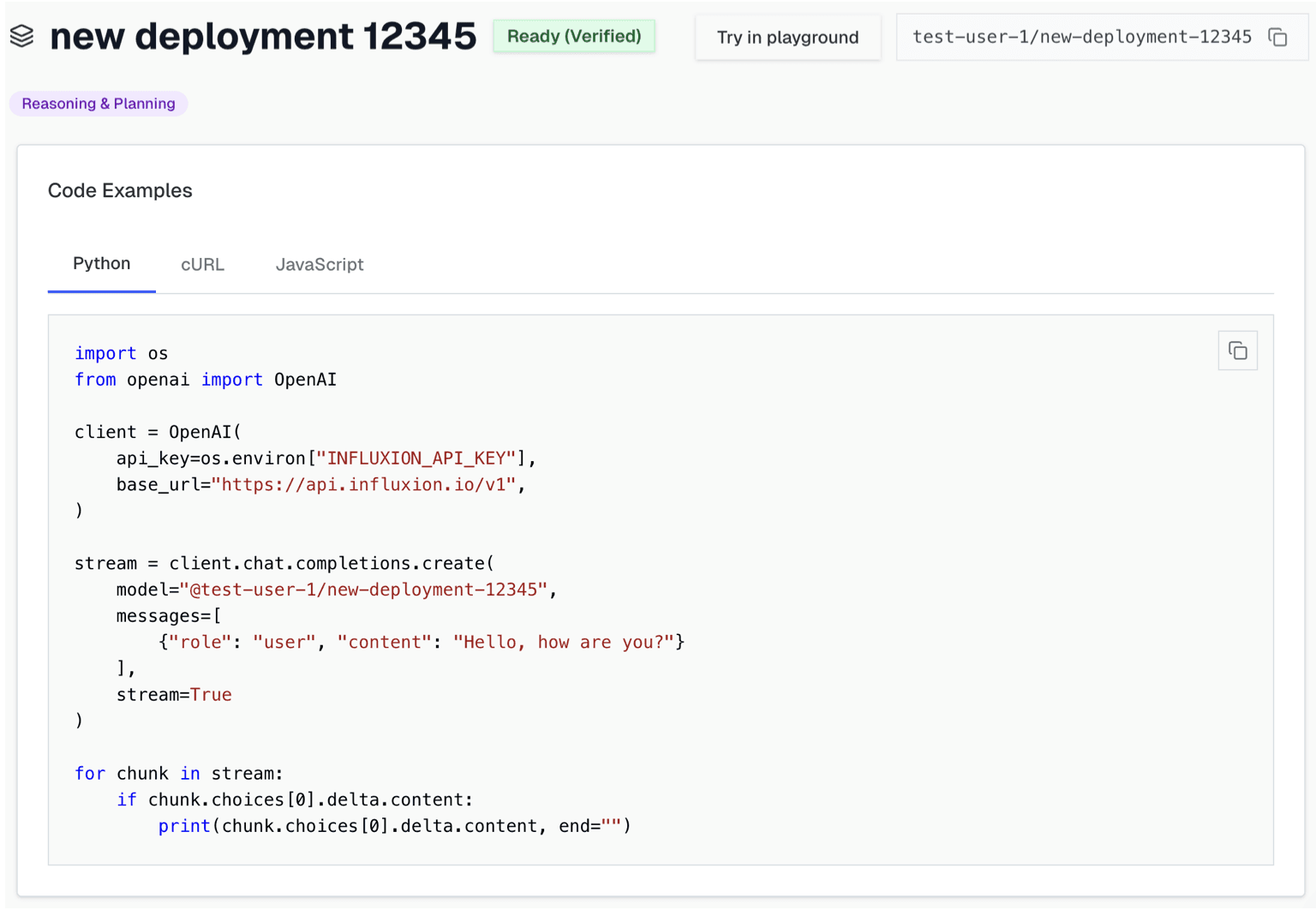
The system learns from live workloads, runs automated experiments, and adapts routing and prompts as requirements and usage evolve. Your AI stays accurate, reliable, and compliant as it scales
We Handle the Complexity of Deploying, Operating, and Improving AI in Production
So teams focus on building AI features, not managing models and infrastructure.
No more benchmarking marathons, prompt guesswork, or fragile pipelines to maintain.
Our runtime continuously refines model selection, routing, and prompts as conditions evolve — without breaking your interface.
When model behaviors change, workloads evolve, or prompts drift, Influxion intelligently responds in real-time so you don't have to.
Influxion integrates evaluation, routing, prompt optimization, drift detection, and safety into a single unified control layer.
An integrated AI gateway lets you get started instantly with any model from the provider or platform of your choice.